Una rápida introducción a HTML
HTML siempre ha sido un lenguaje bastante permisivo en donde los navegadores suelen suplir los errores u olvidos de los programadores con decisiones propias con el principal objetivo de que la página web se haga visible (para el navegador esto es lo fundamental) y del mejor modo posible (para el navegador, esto viene en segundo término) , aunque no sea del modo esperado por el diseñador. Las razones de este comportamiento difieren bastante de las típicas aplicaciones informáticas, en donde un error de compilación del código suele dar como resultado un mensaje de error más o menos críptico y nada más. La explicación de este comportamiento en el entorno de la navegación por Internet es para facilitar su uso por parte de todo tipo de personas y por eso los navegadores siempre intentan hacer todo lo posible por mostrar la página.
¿Qué sabemos de un documento HTML?
A continuación se muestra un ejemplo básico de una página HTML, primero su presentación en un navegador y después su código.
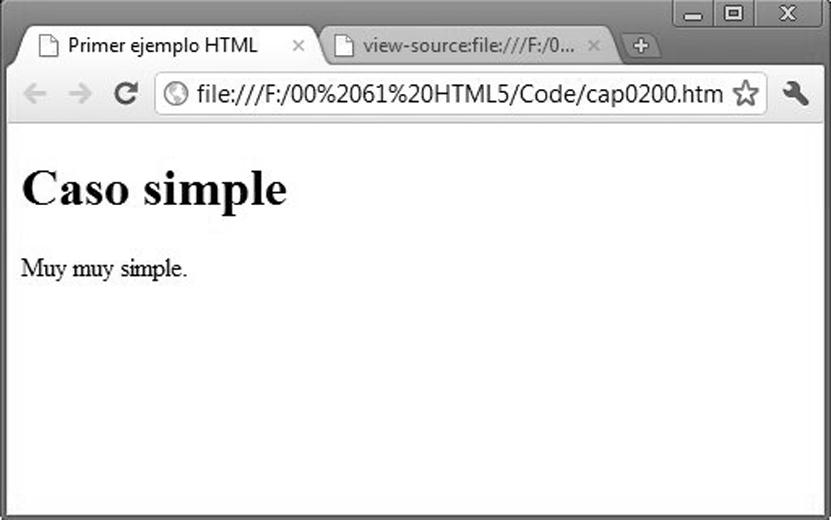
¿Cómo se generó esta página?
Muy fácil, estos son los pasos:
1. En un bloc de notas o cualquier procesador de texto se introdujo este texto:
<!DOCTYPE html>
<html>
<head>
<meta charset=»UTF-8″>
<title>Primer ejemplo HTML</title>
</head>
<body>
<h1>Caso simple</h1>
<p>Muy muy simple.</p>
</body>
</html>
El navegador «interpreta» el código del archivo y genera el contenido visual en la pantalla. El modo de interpretar el código entre los distintos navegadores no es exactamente el mismo, aunque se tienda a la estandarización, por lo que la visualización puede variar según el entorno utilizado para visualizar la página.
El lenguaje HTML
Desde el punto de vista del programador web, HTML es un lenguaje simple y bastante estructurado en la forma. El código resultante suele ser fácil de seguir y de mantener; los principales problemas del codificador comienzan cuando se dejan atributos sin codificar y es el navegador el que se encarga de «llenar los vacíos» con sus valores por defecto (que no siempre son los que esperamos ni deseamos). Esto se agrava si tenemos en cuenta que cada tipo de navegador, e incluso a nivel de versión, suele asignar sus propios valores por defecto y que no siempre son coincidentes.
Los documentos HTML están compuestos por una estructura de elementos denominados etiquetas y por texto. Las etiquetas tienen en general una definición de apertura y otra definición de cierre, por ejemplo, <BODY> y </BODY>, pero algunas de las etiquetas de cierre, en ciertos casos, se pueden omitir.
Concepto de etiquetas
Las etiquetas pueden anidarse de manera que su contenido queda encerrado por etiquetas de nivel superior.
Nunca una etiqueta abierta dentro de la definición de una etiqueta de nivel superior quedará pendiente de cerrarse si se define el cierre de la etiqueta que la anida.
Un ejemplo dejará claro esta definición. Esto no se permite:
<body>
<h1>Ejemplo incorrecto</body>
</h1>
La especificación del estándar define un grupo amplio de etiquetas que HTML puede interpretar y qué atributos tiene cada tipo de etiqueta. El estudio de estas etiquetas, al menos de las más utilizadas, es el tema del libro.
Concepto de atributos de las etiquetas
Mencionamos los atributos de las etiquetas pero aún no sabemos qué son exactamente: podríamos definirlos como parámetros que nos permiten configurar el modo en que actúan las etiquetas.
Los atributos, cuando son necesarios, siempre se incluyen en la etiqueta de apertura (nunca en la etiqueta de cierre).
Los atributos están compuestos por dos partes: nombre y valor, separados por un signo «=». Si el valor se omite, por ser una cadena vacía, puede omitirse también el signo «=». Por ejemplo:
<meta charset=UTF-8>
<input name=id1 disabled>
<!– lo que es igual a …>
<input name=id1 disabled=»»>
Si el valor contiene espacios, comillas simples o dobles o algunos signos especiales (<, >, =), entonces deberán utilizarse comillas obligatoriamente.
Resumiendo, las reglas de los atributos son las siguientes:
l Los atributos, cuando se utilizan, van después del nombre de la etiqueta de apertura; nunca en la etiqueta de cierre.
l Para asignar un valor al atributo, el nombre del atributo debe ser seguido por el signo =.
l El valor del atributo sigue inmediatamente después del signo =.
l El valor del atributo se puede encerrar entre comillas simples o dobles.
l El atributo de tipo booleano es el que simplemente utiliza el nombre del atributo (sin signo = ni valor). Su presencia o no presencia es lo que lo define. En el ejemplo visto, disabled se considera un atributo booleano.
Estructura jerárquica del documento
Cuando los navegadores interpretan el código HTML lo convierten a un modelo de objeto DOM (Document Object Model) que es la representación en memoria del documento.
La estructura del modelo utiliza un esquema en forma de árbol con distintos tipos de nodos y un nodo raíz.
Si esquematizamos el código HTML de la sección anterior nos quedaría esta estructura, en donde la etiqueta html es el elemento raíz del árbol DOM.
DOCTYPE
html
head
meta
title
texto
body
texto
h1
texto
p
texto
Del elemento raíz dependen directamente dos nodos: head y body. El elemento head contiene al elemento meta y al elemento title, que contiene, por su parte, un texto de título. El elemento body contiene un elemento h1 y un elemento p.
El árbol DOM se puede gestionar mediante código de programación con un lenguaje de scripts, por ejemplo, javascript; para incluir código de script se utilizan etiquetas script. Cada etiqueta HTML, vista como objeto DOM, se puede manipular desde código de programa.
<script>
// carga una imagen
var ptx = document.createElement(‘img’);
ptx.src = ‘mapa.png’;
…
Cómo se conoce el código fuente
Los navegadores muestran la página web resultante de interpretar el archivo HTML recibido. Para saber qué es lo que hay «detrás» de esa página, es decir, el código HTML que la genera, es necesario visualizar el código fuente.
Todos los navegadores tienen la opción de mostrar el código fuente de la página que se está visualizando. En todos los navegadores es posible, pero en cada caso se hace de maneras ligeramente diferentes, por ejemplo, en Internet Explorer se siguen estos pasos:
1. Se hace clic en el menú Ver/Código fuente.
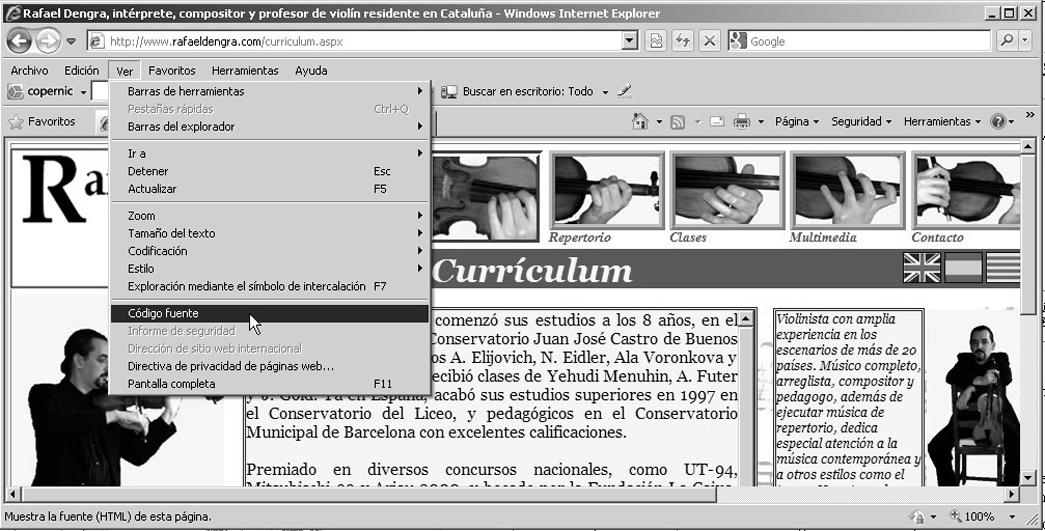
2. Se visualiza el código fuente:
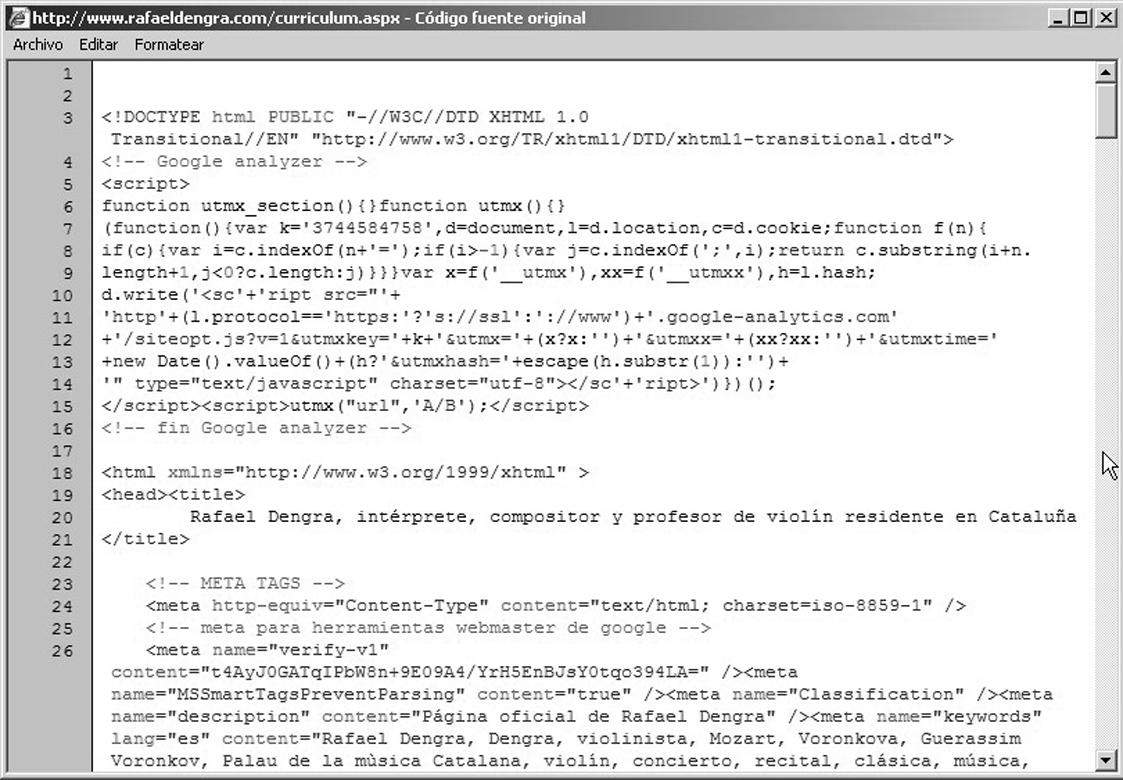
En la fase de aprendizaje resulta muy útil investigar el código fuente de las páginas web que nos llamen la atención y que queramos ver cómo está resuelta por el desarrollador.
Este artículo está tomado del libro HTML 5 Curso de iniciación, si le ha interesado se puede adquirir en Amazon en formato kindle y /o en formato impreso.
