En este artículo nos centraremos en las tareas del diseño lógico de una base de datos para enseñar a descubrir de dónde surgen las tablas de una base de datos y de qué manera toma forma una tabla compuesta de campos.
En la segunda parte del artículo analizaremos los objetos de datos y los dotaremos de los métodos necesarios para utilizarlos en las aplicaciones; el análisis de estos objetos no nos proporcionarán un objeto (clase) definitivo ya que seguramente tendremos que añadir algunos métodos difíciles de prever en una etapa tan temprana del diseño de la aplicación.
| Los objetos de datos se convertirán así en clases con propiedades (las columnas de las tablas) y métodos (las funciones para utilizar el objeto). |
Un método para el diseño de bases de datos
Por lo ya adelantado en el artículo anterior, la tarea de diseño de una base de datos puede describirse con una secuencia bastante definida de pasos que en este artículo analizaremos en detalle:
- PASO 1: Descubrimiento de las entidades de nuestra aplicación: dicho en otros términos, qué tablas necesito en mi base de datos.
- PASO 2: Definición de las propiedades de las entidades: es decir, qué columnas debe tener cada tabla.
- PASO 3: Análisis y definición de las relaciones entre las tablas.
- PASO 4: Normalización de la base de datos.
- PASO 5: Desnormalización de la base de datos.
Paso 1: cómo descubrir qué tablas necesito en mi base de datos
Cuando se establece el diseño de una base de datos relacional, lo primero que debemos hacer es buscar qué objetos debería contener la base de datos, o modelo de datos. Por objetos se entiende aquellos que representan a los clientes, a los pedidos y al catálogo de libros que son los que encontraríamos en un sistema de pedidos básico. A veces puede resultar difícil identificar estos objetos, especialmente si se trata de nuestros primeros objetos de base de datos relacionales y cuando se trata de una base de datos no tan evidente y conocida como la de una gestión de pedidos.
| El modelo de datos surge de la identificación de los elementos importantes del sistema (las entidades que luego serán las tablas de la base de datos), las propiedades de estos elementos (los atributos que luego serán las columnas de las tablas) y cómo se relacionan estos elementos entre sí. |
Para explicar cómo desarrollar un modelo de datos lo mejor es utilizar un ejemplo práctico.
Supongamos que en nuestras manos tenemos el diseño de una aplicación de comercio electrónico. Evidentemente como analistas de sistemas podríamos realizar una descripción literal de una aplicación genérica de este tipo:
|
"Nuestro comercio electrónico es una librería. Cada libro pertenece a una sección de la librería. Las secciones están organizadas de manera jerárquica, siendo la sección principal la propia librería. Cada libro tiene una serie de atributos, muchos de los cuales se repiten en los distintos productos (por ejemplo, imagen, precio, peso, autor, cantidad de páginas, editorial). Los visitantes/clientes de nuestra librería virtual exploran nuestro catálogo realizando búsquedas por sección o buscando directamente un libro determinado a partir de las características que lo describen. Cuando el visitante/cliente llega al libro que le interesa visualiza sus características y puede ver también una imagen del libro o un resumen, además, obviamente del precio y el número de páginas. Cuando el visitante/cliente quiere seleccionar un libro lo coloca en la cesta de la compra. La cesta estará compuesta por todos los libros seleccionados en la sesión de compra y cuando están allí se denominan elementos de la cesta. El visitante/cliente puede añadir o eliminar elementos de la cesta o incluso modificar la cantidad de unidades que se quiere comprar. En cualquier momento el visitante/cliente puede abandonar la compra o concretarla. Cuando el visitante/cliente quiere concretar la compra, introduce sus datos personales. Con los datos introducidos se puede calcular el cargo total de la compra, compuesta por el valor de los libros seleccionados, el impuesto y los gastos de envío. Los gastos de envío dependen del tipo de envío, el peso de los libros y de la dirección del envío. Si el visitante/cliente acepta el valor total concreta el pedido (la cesta de la compra se convierte en un pedido efectivo) y se visualiza un recibo/factura, simultáneamente se le envía el mismo documento por correo electrónico. El pedido puede ser servido directamente por un proveedor de nuestra empresa (distribución delegada a un proveedor) o por el propio almacén de la empresa (distribución directa). El almacén que envía el pedido al comprador registra la referencia de la empresa de mensajería que es la que lleva el pedido hasta el domicilio del cliente. ". |
Bueno, como descripción resumida está muy bien, en líneas generales es lo que podría convertirse en una aplicación de comercio electrónico. En la descripción aparecen muchos elementos dignos de mención pero la tarea de un analista sistemas es abstraer lo esencial.
Pero veamos si somos capaces de ser más telegráficos. La técnica para simplificar es fácil.
Supongamos que tenemos que contarle eso mismo a nuestro socio de la consultora pero lo tenemos que hacer desde un teléfono móvil y sólo nos queda batería para medio minuto. Eliminemos todo lo anecdótico y vayamos a lo fundamental. Pongamos en marcha el cronómetro:
|
"Se venden libros. Cada libro pertenece a una sección. Cada libro tiene sus atributos específicos. Los visitantes/clientes exploran nuestro catálogo de libros. El visitante/cliente selecciona libros y los colocan en la cesta de compra que estará compuesta por uno o más libros. Cuando el cliente está de acuerdo con el total de la compra, la cesta de la compra se convierte en un pedido efectivo que se envía al cliente desde un almacén. " |
Tardamos 28 segundos en leer el texto. Como ejercicio está bien. Volvamos a simplificar el texto y ahora resaltemos las entidades relevantes del relato, la primera vez que aparecen en el texto:
|
"Se venden libros. Cada libro pertenece a una sección. Los visitantes/clientes exploran nuestro catálogo de libros, seleccionan libros y los colocan en la cesta de compra. Al finalizar la compra, la cesta de la compra se convierte en un pedido efectivo que se envía al cliente desde un almacén. " |
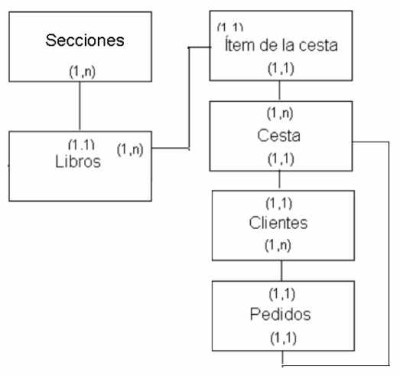
Ya estamos en condiciones de dibujar el primer esquema de nuestro modelo de datos. Cada entidad del diagrama será una tabla de nuestra base de datos. Seguramente aparecerán otras entidades menores cuando refinemos el diagrama y normalicemos el diseño pero podemos estar seguros que éstas son las principales entidades del modelo. ¿Queremos saber la importancia relativa de cada entidad? Es fácil, eliminemos el párrafo en donde aparece la entidad por primera vez y veamos cuál es el mensaje que le llega a nuestro socio de la charla telefónica.
Evidentemente hay entidades más fundamentales que otras. La entidades principales surgen a la luz en el primer diseño, las secundarias aparecerán tarde o temprano. Por ejemplo, la entidad "Sección" no es tan importante, ya que nuestro socio comprendería perfectamente de qué se trata el sistema que tenemos que desarrollar aunque no le digamos que "cada libro pertenece a una sección". La idea fundamental no necesita la palabra "sección" pero estaría incompleta si no se define "libro" o "visitante/cliente".
En realidad, se trata de tener un buen punto de partida para el diseño, no se debe tratar de llegar al diseño final en el primer esquema en borrador. Sería una pérdida de tiempo.
Veamos el diagrama del modelo de datos en su situación actual.
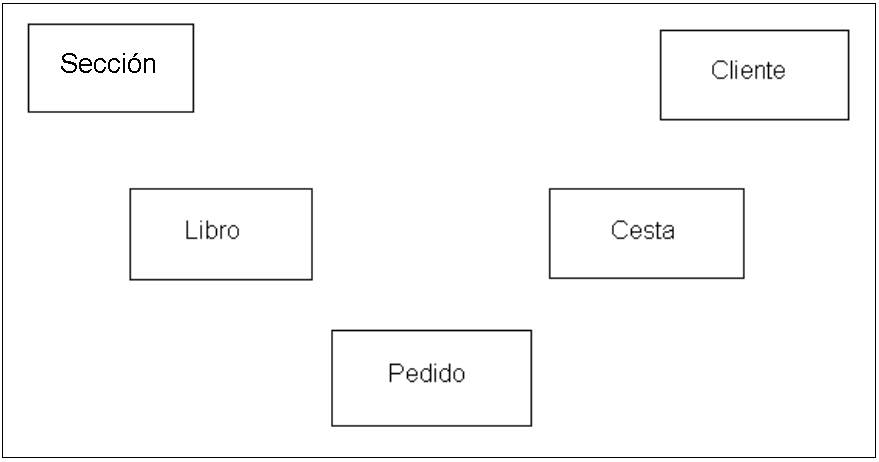
| Aquí hemos trabajado en un diseño que toma como base una librería, pero este ejercicio se podría adaptar a diversos tipos de comercio. Lo que en este modelo de datos es un libro podría ser un producto cualquiera (un disco, una prenda de vestir, un componente electrónico, un juguete, etc.) y lo que aquí se denomina sección podría ser otro tipo de clasificación del producto, por ejemplo, departamento, categoría, etc. Por lo tanto, este modelo de datos se puede adaptar fácilmente a cualquier tipo de comercio. |
Paso 2: El contenido de las tablas
Ahora que tenemos nuestras cinco entidades básicas podemos ver cada una en un mayor detalle, analizaremos qué datos debe contener cada una de las entidades. La tarea es simple, si se siguen dos reglas básicas:
- No debe incluir ningún campo que no necesitemos (esos campos, "por si acaso")
- No debe incluir ningún campo que no añada información a la entidad. Si no añade información es un dato que no debe pertenecer a esa entidad.
Las tablas serán:
Además, por ahora no incluiremos ningún campo de uso técnico; por ejemplo, la fecha de creación del registro o la fecha de última modificación, ya que éstos serán campos que se incluirán posteriormente en todas las tablas.
| Nombre de los campos: aunque en el diseño funcional le podemos dar cualquier nombre a los campos de las entidades cuando estos se convierten en campos de las tablas deben seguir una convención de nombres que se adecuen al sistema de gestión de base de datos que se utilice. Normalmente en SQL no se permiten caracteres especiales (salvo $, # y guión bajo) ni espacios intermedios. La longitud de los nombres está limitada a 128 caracteres pero supongo que es un límite que no nos debe preocupar. Lo ideal es que ya tengamos en cuenta estas limitaciones desde el primer momento en que diseñamos las tablas y que los nombres sean lo más significativo posible. |
Tabla Secciones
Empecemos por la entidad Secciones porque es bastante simple.
Dibujemos la estructura de las secciones de la librería:
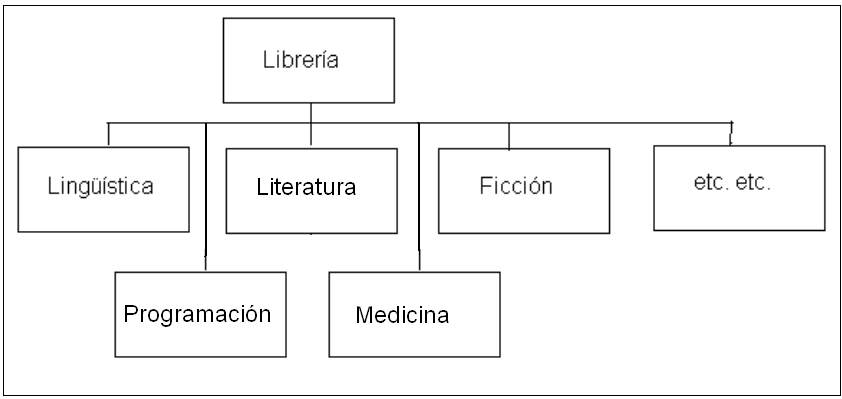
Todas las secciones pueden tener libros, salvo la sección de nivel superior que representa a la totalidad de la empresa.
Como siempre, empecemos a analizar desde la mínima expresión (es una manera de evitar lo superfluo). ¿Cuáles son los campos imprescindibles de la entidad Secciones? Una clave que la identifique y una descripción literal que la defina. Nada más. Si nos ceñimos al análisis no necesitaremos ningún campo más. Obviamente se pueden decir muchas cosas más de una sección de una empresa: ubicación física, teléfono de contacto, responsable, cantidad de empleados, etc. Pero el analista debe usar la creatividad con una causa que lo justifique. Además, las tablas de las bases de datos relacionales permiten el agregado de nuevas columnas con total facilidad.
Bueno, si nos parece apropiado se podríamos también asociar una imagen que represente a la sección, será útil para mejorar el aspecto de la interfaz de usuario. Ahora definiremos los campos con los nombres que luego utilizaremos para definir la tabla en la base de datos.

Tabla Libros
La entidad Libros es más extensa y compleja que la anterior. Es la representación del catálogo de la librería. Veamos ahora sí, los campos de la entidad Libros:

Aparece aquí una relación entre la tabla Libros y la tabla Secciones; la relación se corresponde a una clave externa que relaciona ambas tablas.
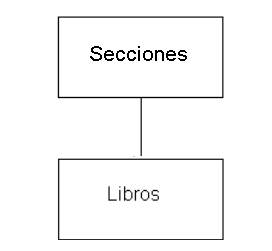
Tabla Clientes
Esta entidad es importante pero funcionalmente simple (en realidad, una base de datos relacional bien diseñada no debe ser compleja).
En esta entidad debemos almacenar los datos personales del cliente, no guardaremos aquí los datos de las operaciones que realiza; para eso tendremos otras tablas específicas. Por lo tanto, concentrémonos ahora en los datos que definen a un cliente:
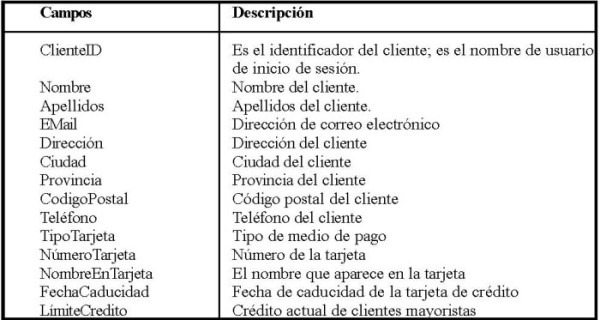
El conjunto de campos que hace referencia a la tarjeta de crédito tiene una consideración especial debido a su naturaleza:
- Primero, porque no es un dato que define estrictamente al cliente, ya que un cliente puede comprar una vez con una tarjeta de crédito y otra vez con otra. Aunque esto también podría decirse de la dirección del cliente.
- Segundo, por razones de seguridad.
Evidentemente, tenemos varias opciones:
- No almacenar el conjunto de campos en la tabla Clientes: simplemente los guardamos en variables internas de la página que se destruyen con la sesión. En realidad es un dato útil en un momento determinado y después su utilidad es relativa. A la mayoría de los compradores por Internet no les hace gracia ver su número de tarjeta en el formulario de compra llenado automáticamente por la aplicación lo que demuestra que se lo ha mantenido desde la última compra. Hay quienes lo aceptan, pero también hay personas que dejan de comprar en un sitio por ese motivo.
- Almacenar el conjunto de campos en la tabla Clientes para simplificar la entrada en la siguiente compra
- Almacenar el conjunto de campos en la tabla para simplificar la entrada en la siguiente compra pero ocultando con asteriscos los cuatro últimos dígitos
Pero, por ahora, a pesar de nuestras dudas, reservamos estos datos en la tabla Clientes y cuando lleguemos a la parte dedicada a la seguridad analizaremos cuál es la mejor opción para nuestro caso. De todas maneras, en nuestra base de datos quedarán registrados los datos del medio de pago (tipo, número, fecha de caducidad de la tarjeta) pero en una tabla menos expuesta que la tabla de Clientes. Es imprescindible que esa información quede registrada en algún sitio para futuras comprobaciones contables con nuestra entidad bancaria.
Tabla Cesta
La cesta de la compra nos permite acumular los libros que se van seleccionando a lo largo de la sesión de compra. Por lo tanto, la cesta de la compra representa la compra global de un cliente y se corresponderá con una tabla denominada Cesta. Pero nosotros también necesitaremos tener también una entidad que nos brinde el detalle de los libros seleccionados, por lo tanto, surge la necesidad de crear una segunda entidad dependiente de la cesta para representar cada uno de sus elementos.
Un cliente determinado puede tener sólo una cesta de compra activa por sesión.
| Campos | Descripción |
|---|---|
| CestaID |
Es el identificador de la cesta; es un valor de tipo identificador único asignado por el gestor de base de datos. |
| ClienteID | Es el identificador del cliente al que pertenece la cesta. |
| FechaCreación |
Es la fecha de creación de la cesta, servirá para las rutinas de depuración; un cliente se puede desconectar por algún motivo pero si vuelve a conectarse dentro de las 24 horas (el plazo es arbitrario) podrá encontrarse con la cesta que había generado hasta el momento. Pasado ese plazo, por procesos de limpieza automáticos se encargarán de eliminar las cestas abandonadas. |
| Estado |
Indica si está activa (en proceso de compra) o cerrada (en proceso de pago). |
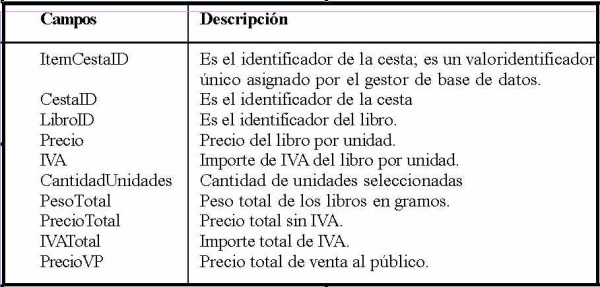
Tabla ItemCesta (elemento de cesta)
Cada vez que un cliente añade libros a la cesta lo que está provocando es una inserción a una tabla ItemCesta (o, según la implementación que se desarrolle, se puede añadir un elemento a un array en memoria y postergar la grabación de la tabla para más adelante, por ejemplo, al producirse el pago de la cesta). Cada fila de esta tabla es una línea de detalle de la compra. El primer libro que se agrega a la cesta deberá también crear primero a la propia cesta.
¿Qué datos se guardan en esta tabla? ¿Es suficiente con el código de libro y la cantidad de unidades?
¿Qué pasaría si durante la sesión de compra del cliente, después que ha elegido el libro A, con un precio unitario de 40 euros, el administrador del sitio actualiza la lista de precios e informa que ese libro a partir de hoy mismo vale 43 euros? Seguramente, ese cliente no le gustará la sorpresa cuando quiera concretar la compra.
Cuando se factura el precio de un libro se debería respetar el precio del momento de la selección. Por lo tanto, ése sería otro campo que se podría guardar en la tabla ItemCesta.
También se podría limitar la tarea del administrador y sólo permitir que cambie los precios (el catálogo en general) con la base de datos fuera de línea y así se evita el problema del cambio de precios en la cesta pero eso hace que nuestro comercio electrónico tenga que estar no operativo durante un cierto tiempo del día y a veces esta no es una alternativa aceptable.
| La actualización de los precios del catálogo puede suceder en cualquier momento, incluso en el medio de un proceso de compra de un cliente. No debemos permitir que esa actualización afecte al precio de las compras que están en la cesta. |
Veamos ahora el diagrama de las entidades que rodean a la cesta de la compra.
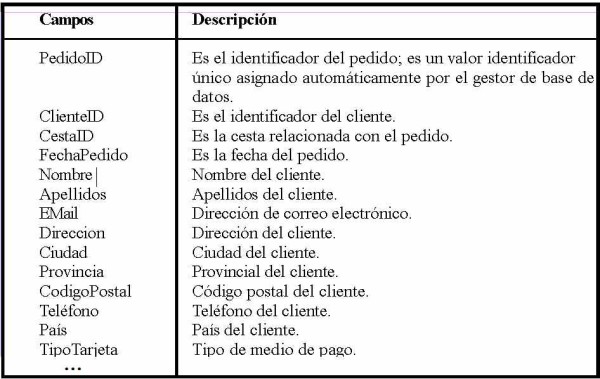
Tabla Pedidos
Cuando el comprador ha pagado por su compra la cesta de compra se convierte en el pedido. A partir de ese momento la cesta de compra cambia de estado, pasando de abierta a cerrada, y se genera un pedido.
¿Pero por qué vamos a duplicar la información de la tabla Clientes en la tabla Pedidos? ¿Acaso no se trata de una tabla permanente?
La respuesta es sí y no.
La tabla Clientes es permanente porque el registro no se eliminará nunca. Pero no nos sirve porque esa información del cliente es la información vigente y puede cambiar en el futuro. Puede cambiar su domicilio, su dirección de correo electrónico, etc. Y para ciertas cosas, es importante que registremos la información vigente al momento de la compra (algo así como la foto del momento). Primero por razones contables (la factura contiene mucha de esa información personal y debe quedar registrada), segundo por si surgen reclamaciones del banco o del propio cliente. En definitiva, no tenemos más opciones que generar un registro bastante parecido al registro del cliente.
La fecha de envío y la referencia de la empresa de mensajería son datos necesarios para que el cliente conozca la situación de su compra y, en caso de demora, poder realizar una reclamación.
Estados de un pedido
Hemos incluido el campo Estado para poder hacer un seguimiento del proceso del pedido. El estado indica la situación del pedido dentro del flujo del proceso. Estos son los estados posibles que puede tener nuestro pedido dentro de la aplicación:
- Pendiente
- Pagado
- Enviado
- Recibido
- Devuelto
- Anulado
| ¿Por qué no usar una tabla para contener los estdos de un pedido? En realidad es convenientecrear tablas de campos que pueden tener una lista de valores determinada; por ejemplo, países, tipo de tarjeta o tipo de envío. Su uso nos facilitará las validaciones y la codificación será más limpia y segura. En esta aplicación utilizaremos la tabla Estados. |
Tabla Estados
La tabla es muy simple, tiene un campo que indica el tipo de estado. Los únicos estados válidos de un pedido son los que figurarán en esta tabla.
| Campos | Descripción |
| EstadoPedido | Indica el estado del pedido. |
Paso 3: Definición de relaciones
En las tablas relacionales cada tabla tiene una columna (o combinación de columnas) que actúa como clave primaria y que permite la identificación unívoca de cada fila de la tabla. Al diseñar las tablas hemos ido indicando qué columna actúa como clave primaria y nos aseguramos que esa clave no pueda tener duplicados.
En la tabla Libros la elección fue fácil, no hay dos libros con el mismo ISBN (campo de diez o trece dígitos, según el año de edición del libro).
En la tabla Secciones teníamos distintas alternativas: el nombre de la sección, el identificador contable de la sección, un número de autoincremento, un identificador único tipo GUI. Optamos por la alternativa de utilizar el nombre de la sección como clave de la tabla.
En la tabla Clientes la decisión es más compleja. ¿Qué podemos utilizar como clave del cliente? Hay varias opciones y cada una tiene sus ventajas y desventajas.
- Usuario: identificador elegido por el usuario para abrir una sesión en el sitio Web. La ventaja de este campo es que se unifica la clave que se utiliza para identificar al cliente en el sitio Web con la clave de la tabla Clientes.
- Apellidos y nombre: esta sería una elección natural pero puede presentar duplicados. Sin ánimo de ofender ¿Cuántos José García hay en mi barrio?
- DNI: dentro de un mismo país no debería haber duplicados (aunque en España, no sé cómo, lo han logrado -y mira que es fácil numerar) , pero además ¿qué pasa con los números de los DNI de extranjeros?
- Teléfono: no todos tienen una línea personal (teléfonos familiares).
- Número de la tarjeta de crédito: definitivamente ni pensarlo. Si elegimos esta opción, que nos daría una clave única para cada cliente, habremos elegido la mejor manera de espantar clientes potenciales. A nadie le agrada andar tecleando esta información en Internet ante cada inicio de sesión. Hay que olvidarse de esta posibilidad y descartarla de plano, salvo que nuestra empresa sea Visa o un banco.
- Email: parece una buena opción, de hecho muchos sitios Web han elegido esta opción. Pero qué sucedería si el cliente quiere cambiar de dirección de correo, ¿crearíamos un nuevo registro con la nueva clave? ¿Qué pasaría con toda la información histórica del cliente?
- Un valor identificador único asignado por el gestor de base de datos: esto nos asegura que no habrá dos claves iguales pero la manipulación de los datos GUI es muy pesada y la presentación del dato en pantalla deja mucho que desear.
| Nuevamente parece más limpia la solución de utilizar el nombre de usuario y no preocuparnos si el cliente cambia su dirección de correo. |
De las claves primarias a las claves externas
Cuando cada una de las tablas tiene su clave primaria y cada clave primaria puede ser potencialmente una clave externa en otra tabla que le haga referencia. Veamos las claves externas de nuestra base de datos:
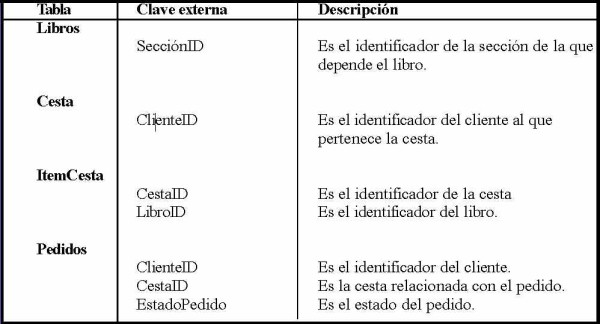
¿Por qué las tablas Secciones y Clientes no tienen claves externas?
Porque las filas de Secciones y Clientes pueden existir sin necesidad de depender de filas de otras tablas. Un libro debe depender de una sección, una cesta debe depender de un cliente, un ítem de cesta debe depender de una cesta, etc. Pero un cliente puede existir aunque no haya libros ni cestas ni secciones.
| La clave externa genera una relación de dependencia. |
¿Pero esto quiere decir que la tabla Clientes nunca tiene claves externas? No, por supuesto. En la base de datos podríamos tener una tabla de países y forzar la relación entre el país del cliente y esa tabla de países; con esto nos aseguraríamos que el campo países de los clientes estaría validado contra esa tabla.
| Las relaciones entre entidades pueden ser 1 a 1, 1 a n o n a n. |
Paso 4: Normalización de la base de datos
Veremos 3 formas normales:
Se denomina normalización de una base de datos relacional al proceso de ajuste del diseño de la base de datos mediante la eliminación de la información redundante y otros errores de diseño generalmente mediante la redefinición de las tablas componentes y la subdivisión de tablas.
El proceso de normalización tiene cinco niveles que se denominan formas normales. En la práctica se utilizan los tres primeros niveles (primera forma normal a tercera forma normal) ya que los dos últimos niveles son de difícil implementación y rara vez se apela a tal grado de purismo técnico.
Por razones de espacio y objetivos del libro no nos vamos a extender en este tema pero por supuesto existen muchos libros específicos sobre bases de datos relacionales que lo explican en detalle.
Haremos una breve definición de qué condiciones debe cumplir una base de datos para encontrarse debidamente definida para cada forma normal. Después de cada definición observaremos nuestra base de datos y veremos si hemos cometido algún «pecado de diseño" y lo corregiremos. Por supuesto, es más grave que una base de datos no esté en 1NF (primera forma normal) que no esté en 2NF, y así sucesivamente. Una base de datos que cumpla con 3NF (y de hecho con las dos anteriores) se considera que tiene un diseño relacional correcto.
| Sí, cuando se llega a un diseño 3NF se puede decir que tenemos un diseño relacional correcto; pero esto no implica que luego ajustemos ciertas decisiones para obtener mejores rendimientos y dentro de esos ajustes puede haber algunas decisiones que hagan que la base de datos deje de estar en la forma 3NF. Pero esto ocurrirá por decisión propia y no por falla de diseño. |
Primera forma normal (1NF)
Una base de datos está en 1NF cuando en las filas de las tablas no existen campos repetitivos. Por ejemplo, definiremos una tabla Cesta algo diferente a la creada anteriormente (que estaba correctamente diseñada):
|
Columnas de una hipotética tabla Cesta CestaID ClienteID ItemCesta1 Precio 1 ItemCesta 2 Precio 2 … |
En nuestro caso no hemos caído nunca en este error. De haber creado una tabla Cesta de esta manera habríamos corregido el problema subdividiendo la tabla en dos (Cesta e ItemCesta) y de esa manera hubiesen desaparecido las repeticiones.
Con el uso de una tabla ItemCesta que almacena un elemento por fila estamos facilitando la programación al despreocuparnos de la limitación física que impone que en una fila se puedan almacenarse n elementos, que aunque n sea un número grande siempre será un límite. Obviamente también existe un beneficio en el rendimiento de la base de datos cuando se quiere realizar una búsqueda en la entidad ItemCesta. No es lo mismo que el sistema de gestión de base de datos pueda acceder por índices, como lo haría con la tabla ItemCesta, que tenga que navegar por una larga matriz de datos incrustada en las filas de una tabla.
Segunda forma normal (2NF)
La segunda forma normal se refiere a la elección del campo clave de la tabla. El campo clave (clave primaria) identifica de modo unívoco a una fila de la tabla: no hay dos filas con la misma clave. Esto ya lo sabíamos.
¿Qué sucede si el campo clave está formado por la combinación de dos campos? Exactamente lo mismo: es perfectamente posible que la clave primaria esté compuesta por 1, 2 o más campos que se analizan en conjunto. Por ejemplo, nuestro número de cuenta bancaria suele tener el formato banco-oficina-nro.cuenta-dígito verificador: es una clave compuesta por cuatro campos y normalmente es la clave primaria de la tabla de cuentas bancarias.
¿Qué recomienda la 2NF? Que ningún campo de la tabla debe depender únicamente de una parte de la clave primaria. Veamos cómo se puede cometer un error de diseño que nos hace caer en una violación de la segunda forma normal.
Para que una tabla esté en 2NF además debe estar en 1NF.
|
Columnas de una hipotética tabla CuentaBancaria BancoID (clave primaria) OficinaID (clave primaria) NroCuentaID (clave primaria) DígitoID (clave primaria) Apellido Nombre …. DirecciónOficinaBanco |
¿La dirección de la oficina del banco depende del nro. de cuenta del cliente o simplemente de banco-oficina? Por supuesto, un cambio en el número de la cuenta no hace que la dirección de la oficina varíe, ya que la dirección de la oficina depende de la composición del código de banco y de oficina. Pues bien, en este caso se produce una violación de la 2NF.
| ¿Cómo se soluciona? Sacando la columna DirecciónOficinaBanco. Seguramente ese dato figura en la tabla Oficinas del banco y con que esté allí ya es suficiente; allí lo buscaremos cuando haga falta. |
Se dice que una tabla está en la tercera forma normal si está en 2NF y además todas las columnas de una fila dependen de la clave primaria y ninguna columna depende de una columna que no sea clave primaria. Veamos una hipotética tabla ItemCesta en la que aparece un campo GastosEnvío.
|
Columnas de una hipotética tabla ItemCesta ItemCestaID CestaID Producto Precio CantidadUnidades GastosEnvío |
¿Está mal que ese campo esté allí? ¿Estamos violando la 3NF?
La respuesta es: quizá sí y quizá no.
Para responder correctamente deberíamos saber de qué depende el cálculo de gastos de envío.
Si en la definición funcional se indica que los gastos de envío de una compra dependen de la distancia entre la dirección del cliente y los almacenes centrales de distribución: el gasto de envío es uno para toda la cesta y no depende de un ítem de cesta.
Pero, si en la definición funcional se indica que los gastos de envío de una compra dependen del precio de cada uno de los productos comprados estaría bien tener un parcial a nivel de ítem de cesta y luego un total a nivel de cesta.
Por lo tanto, la corrección de esta anomalía de diseño es mover el campo a la tabla correcta y así desaparece la violación 3NF.
Paso 5: Desnormalización de la base de datos
No es que se haya perdido el juicio. Por un lado se busca que las bases de datos estén normalizadas para evitar anomalías en el acceso y en las actualizaciones pero también existen otros factores que pueden recomendar que se tenga que dar un paso atrás en la normalización.
Por ejemplo, ¿para qué necesito tener un campo totalizador de gastos de envío en la cesta (referencia a la sección anterior) si ese valor siempre lo puedo obtener por cálculo de sumatorio de gastos de envío a nivel de ítem de cesta? La respuesta es: por comodidad y rendimiento; ya que evito un bucle de sumatorio para calcular el valor cada vez que lo deba mostrar.
¿Podría añadir una descripción del producto en cada una de las filas de ItemCesta?
Desde el punto estricto la descripción del producto es un campo que depende del producto y no del ítem de cesta. Estaríamos violando la 3NF. Las preguntas son: ¿por razones de rendimiento se justifica esa redundancia de datos? ¿Me conviene asumir esa anomalía a cambio de un mejor tiempo de respuesta de la aplicación o de menores accesos a la base de datos? Si las respuestas son afirmativas nada me impide esos pequeños desvíos a la pureza del diseño relacional.
Veamos ahora nuestra tabla Pedidos. Recordemos su diseño:

Parecería que estamos incurriendo en varias violaciones a 3NF.
¿El campo ClienteID depende de la clave primaria PedidoID? ¿O depende del campo (no clave primaria, simplemente clave externa) CestaID?
La tabla Cesta ya incluye la relación Cesta-Cliente, por lo que la aparición de ambos campos en las filas de la tabla Pedidos está incluyendo dos campos no clave con dependencias entre sí.
Todos los datos del cliente de la tabla Pedidos son redundantes ya que si fuésemos a la tabla Cesta obtendríamos la clave del cliente (ClienteID) y desde allí podríamos ir a la tabla Clientes para obtener todos los datos que estamos incluyendo de modo redundante (¿redundante?) en la tabla Pedidos.
En realidad, el dato verdaderamente redundante en esta tabla es la clave del cliente (ClienteID) porque lo podríamos obtener del modo explicado en el párrafo anterior. Los datos nombre, apellidos, email, dirección, etc. son datos que podrían variar a lo largo del tiempo en la tabla Clientes y que figuren en la tabla Pedidos está justificado porque se quiere guardar el estado de esos datos del cliente en el preciso momento del pedido.
Entonces, ¿por qué violamos la 3NF con la inclusión del campo ClienteID?
La respuesta es que es una desnormalización que hemos realizado para simplificar algunas sentencias SQL con las que se quieren consultar los pedidos de un cliente sin pasar por la tabla Cesta. Obviamente, podríamos haber optado por no incluir ese campo pero para acelerar los accesos nos viene bien que esté allí.
|
|
|
|
